How We Built an AI Chatbot for Navigating Our Documentation

At Enable Banking, our public documentation is extensive and growing every day. We take pride in its amount and quality, but even with organised and well-structured FAQs and technical guides, it’s easy to forget where to find that one crucial snippet of information. To spend less time searching for relevant information and more time solving real problems, we developed a custom AI chatbot that allows us to essentially have conversations with our documentation. Along the way, we learned about different approaches and what makes our documentation both human and machine-readable.
Powered by RAG: Our Secret Sauce
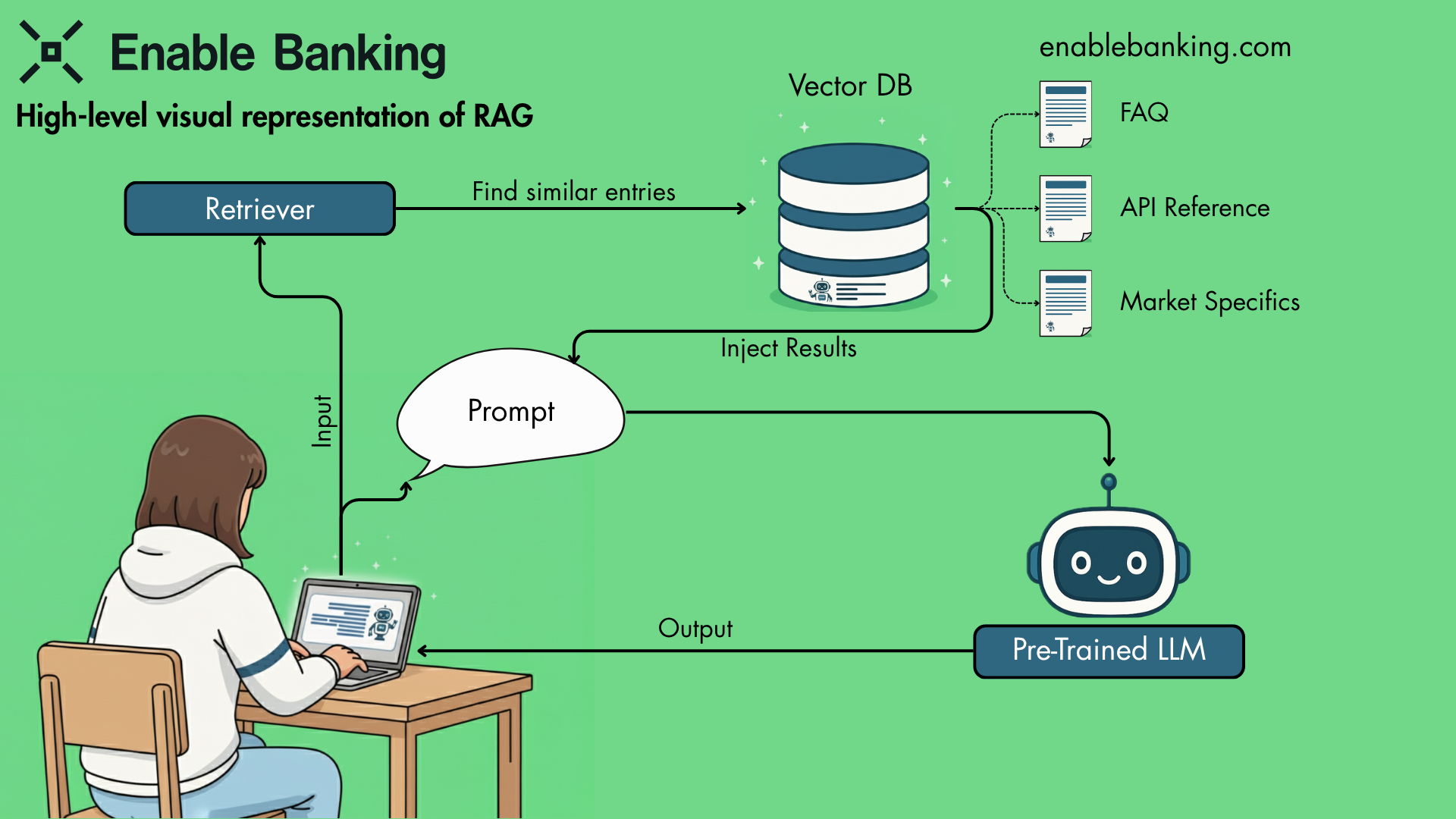
The tool is based on Retrieval Augmented Generation (RAG), an approach popular for building context-aware LLM applications. This is exactly what we need to solve our issue: an AI tool that can fetch very specific information without the overhead of training our own large language model. One of the biggest limitations to using publicly available LLMs like ChatGPT for our use case is that they don’t know our docs by default because they are primarily trained on static datasets sourced from the internet, and their knowledge is limited to the time period and data sources covered during the training. RAG combines the user's prompt with relevant parts of our documentation, resulting in answers that are relevant, up-to-date and actually useful.
The RAG system is built using these elements:
Retriever: Searches the database for similar entries to the prompt.
Vector database: A vector database stores pieces of information as lists of numbers (vectors) that capture their meaning, so similar ideas end up close together. Embeddings are the process of turning data into vectors, allowing computers to compare them efficiently.
LLM: a pre-trained Large Language Model used to generate a response.
Our approach to building an Internal Chatbot
There are lots of ways to implement RAG, and the market offers plenty of tools to choose from. Our data pipeline relies on Pinecone, which makes it easy to create and store embeddings in a vector database. We use our website as the source of truth, but as the HTML documents are quite long, we need a smart way to split them in smaller parts (chunks). Given that our documentation is structured clearly by headings, we can use a relatively simple program to split the documents using the LangChain library. The algorithm splits the documents first by headings and then breaks those parts further down into smaller chunks for increased efficiency.
During this step, we also capture useful metadata, like the document title, the path through headings and subheadings, and which part of the content the chunk comes from. This will help the pre-trained LLM understand exactly where each piece of information came from, so it can give accurate, context-aware answers and provide sources for the answers, so the end user can double-check the validity straight from the original entry.
Here’s a code snippet showing how we turn a web page into chunks ready for our vector database:
from langchain_text_splitters import (MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter) from langchain_community.document_loaders import AsyncHtmlLoader from langchain_community.document_transformers import Html2TextTransformer def chunk_html(url): headers_to_split_on = [ ("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3"), ("####", "Header 4"), ] html_content = AsyncHtmlLoader([url]).load() html2text = Html2TextTransformer() docs_transformed = html2text.transform_documents(html_content) splitter = MarkdownHeaderTextSplitter(headers_to_split_on) html_header_splits = splitter.split_text(docs_transformed[0].page_content) # chunk the document entries text_splitter = RecursiveCharacterTextSplitter( chunk_size=300, chunk_overlap=50 ) chunks = text_splitter.split_documents(html_header_splits) return chunks
The chunks are then uploaded to the vector database, using the llama-text-embed-v2 embedding model, which calculates the embedding values for the chunks. At this point, we have computed and saved the vector values for the documents we want to use and are ready to search the most relevant ones.
When the user prompts our chatbot, we search the vector database for the most relevant chunks to that prompt. A single chunk looks something like this:
ID: 5c524ed0-v651-942d-0eas-n00c1l1k5bd2 chunk_text: "implement additional security measures. Among the PSU headers, Psu-Ip-Address (containing the end-user's IP address) and Psu-User-Agent (containing identification of a web browser or an application used by the end-user) are" content_part: 3 context_path: "Frequently Asked Questions > What are the PSU headers in the endpoints for fetching account details," document_title: "https://enablebanking.com/docs/faq" score 0.4665
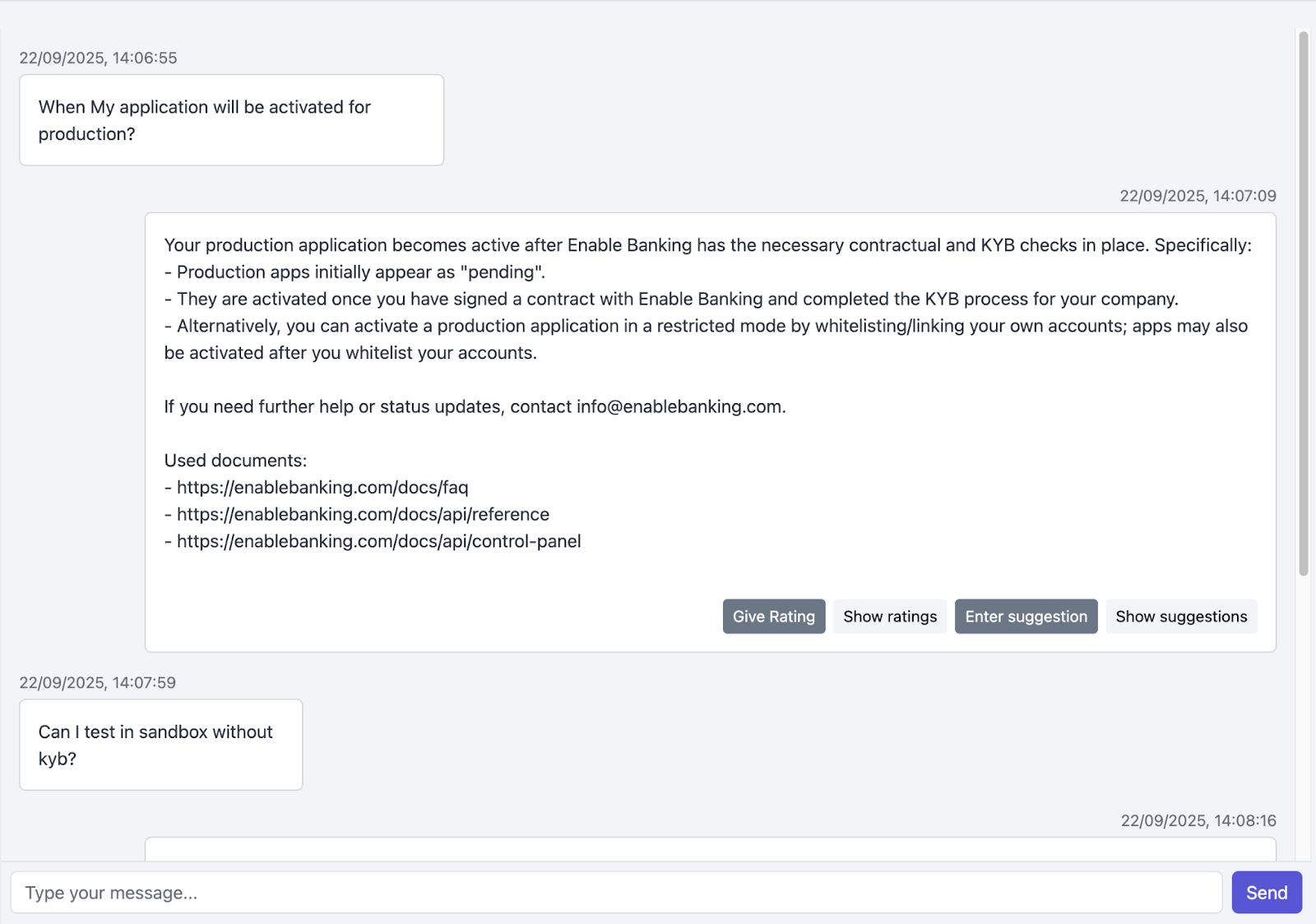
Next, we take the user’s original prompt and pair it with the chunks we retrieved in the previous step. To generate answers, we use OpenAI’s Chat Completion API. This setup allows us to pair the original prompt with a developer message, guiding the LLM to act as a support tool for our team. We add the relevant chunks, message history and original prompt to the GPT-5-mini model and hopefully receive a coherent, context-aware answer.
To keep improving the tool, we also added functionality to let users rate the AI’s answers based on different criteria and provide corrections if needed. These evaluation methods are crucial for refining the tool in future iterations.
Takeaways from implementing our internal chatbot
As a developer, the project was super exciting. It’s clear that we have solid documentation on our website, but sometimes navigating through it can sometimes feel like a treasure hunt. Some entries get buried under the new ones, and valuable info gets lost in the document forest. I see huge potential in the conversational style of finding relevant information, it’s not only faster but also more fun and engaging.
Getting a finished product wasn’t always straightforward, though. Implementing technology that’s new to the dev team requires thorough research, in this case, bouncing back between fine-tuning, experimenting with AI platforms and discussing with experts in the area. In the end, RAG just clicked, giving us the perfect mix of low development overhead and efficiency without breaking the bank.
What really makes this project so rewarding is seeing the concrete business value, which is why I approach this project with passion. I loved collaborating with our support, development and sales teams to gather feedback and iterate ideas. There is something satisfying about building software that you know people will actually use. Implementing a conversational AI tool is also quite personal, as people prefer different kinds of answers; some like humour sprinkled into the text, some prefer strictly business language, for example. Adjusting the answers based on the feedback from several users is an art of its own.
I look forward to further expanding my skills in building context-aware AI systems and improving our ways of working towards automation.
Some of my key lessons I picked up in the implementation process:
Garbage in, garbage out: the tool’s performance is highly dependent on the data quality. If the data is incorrect or outdated, the tool is no better than using a vanilla LLM. If your data sources are complex and unstructured, the chunking strategy requires more care and time.
Size matters: the mini-sized model was a good balance between cost and performance. The larger GPT-5 usually produced answers that were too detailed or long for our use case, and GPT-5-nano lacked in performance.
All in all, this project reminded me why I love building tools that actually make work better, not just flashier. I can’t wait to keep pushing the limits of what context-aware AI can do for us next.

Meet the Author
Eero is a software engineer at Enable Banking and a Computer Science Master’s student at the University of Helsinki. He’s passionate about creating software with real business impact, whether it's connecting banks across Europe through open banking APIs or teaching AI to navigate documentation.